
Introduction
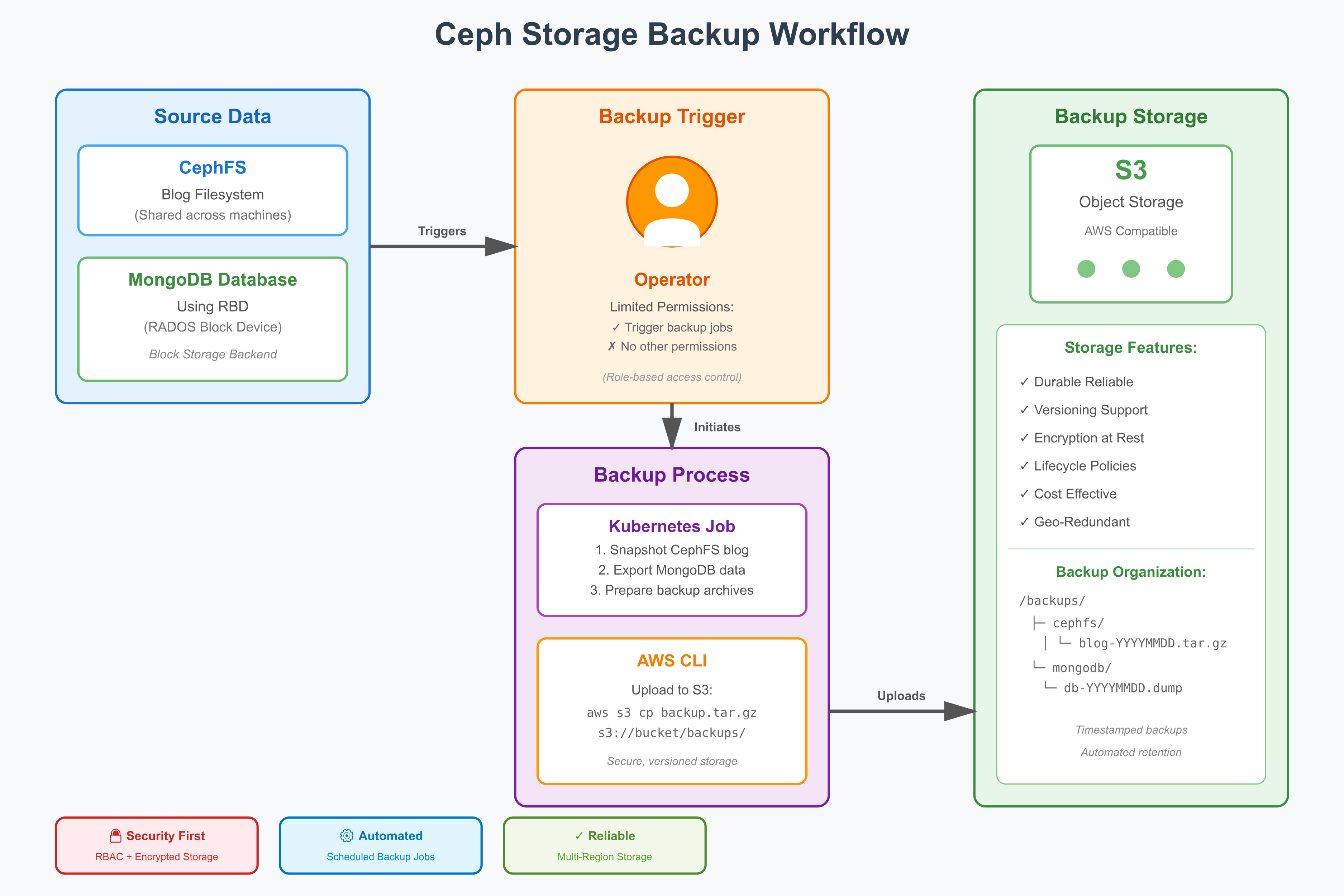
We found out in our previous episodes how to persist data and make it available accross our machines but we haven’t touched on the backup aspects. This article will look at how to backup our blog’s cephfs filesystem and a mongo database which is using the rados block device RBD as block storage. The backup will be triggered by an operator outside of the k8s cluster whose permissions are limited to only trigger the backup job and nothing else. We’ll then use amazon’s CLI to connect to our S3 object storage which we’ll use as our backup storage.
Setting up object storage for our backups
I’ve chosen to go with garage as minio recently decided to not make new docker images available for free anymore.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
services:
garage:
image: dxflrs/garage:v2.1.0
container_name: garage
restart: unless-stopped
ports:
- "3900:3900" # S3 API
- "3901:3901"
- "3902:3902" # S3 UI
# - "3903:3903" # K2V API (optional)
volumes:
- ./garage.toml:/etc/garage.toml:ro
- ./data/meta:/var/lib/garage/meta
- ./data/data:/var/lib/garage/data
# Optional: resource limits
deploy:
resources:
limits:
cpus: '2'
memory: 2G
# reservations:
# cpus: '1'
# memory: 512M
# Optional: healthcheck
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3901/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
networks:
- proxy-net
networks:
proxy-net:
external: true
If you’re not already using a reverse proxy on your VPS you could add this instead to your compose stack
1
2
3
4
5
6
7
8
9
10
11
12
13
(...)
caddy:
build: ./
image: caddy-hz:latest
restart: unless-stopped
ports:
- 443:443
volumes:
- ./data/data:/data:z
- ./data/config:/config:z
- ./data/etc:/etc/caddy:z
environment:
HETZNER_API_TOKEN: $HETZNER_API_TOKEN
And the corresponding docker file to be able to trigger automatic TLS renewals for wildcard certificates
1
2
3
4
5
6
7
8
FROM caddy:2.10.0-builder-alpine AS builder
RUN xcaddy build \
--with github.com/caddy-dns/hetzner
FROM caddy:2.10.0-alpine
COPY --from=builder /usr/bin/caddy /usr/bin/caddy
1
2
3
4
5
6
7
8
9
10
11
12
mkdir -p data/etc
nano data/etc/Caddyfile
cat <<EOF > data/etc/Caddyfile
garage-s3.company.ltd:443 {
tls technik@adata.de {
dns hetzner {env.HETZNER_API_TOKEN}
}
reverse_proxy garage:3900 {
header_up X-Real-IP {remote_host}
}
}
EOF
Configure the garage server with this toml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
cat > garage.toml <<EOF
metadata_dir = "/var/lib/garage/meta"
data_dir = "/var/lib/garage/data"
db_engine = "sqlite"
replication_factor = 1
rpc_bind_addr = "0.0.0.0:3901"
rpc_public_addr = "<your pub ip>:3901"
rpc_secret = "$(openssl rand -hex 32)"
[s3_api]
s3_region = "garage"
api_bind_addr = "0.0.0.0:3900"
root_domain = "garage-s3.company.ltd"
[s3_web]
bind_addr = "0.0.0.0:3902"
root_domain = "garage.company.ltd"
index = "index.html"
[k2v_api]
api_bind_addr = "0.0.0.0:3904"
[admin]
api_bind_addr = "0.0.0.0:3903"
admin_token = "$(openssl rand -base64 32)"
metrics_token = "$(openssl rand -base64 32)"
EOF
And start the service
1
docker compose up -d
Let’s now create a place to store our backups
1
2
3
4
5
6
7
8
9
docker exec -it garage /garage status
docker exec -it garage /garage layout assign -z zone1 -c 30G <id from previous status command>
docker exec -it garage /garage layout apply --version 1
docker exec -it garage /garage key create access-key
# the bucket name should match the website's UI in case you want to store your frontend assets for example
# or your gitlab's registry, artifacts or anything else really
docker exec -it garage /garage bucket create garage.company.ltd
docker exec -it garage /garage bucket website --allow garage.company.ltd
docker exec -it garage /garage bucket allow --read --write --owner garage.company.ltd --key access-key
So once we setup the amazon cli you’ll be able to upload an asset and query it over the UI address
1
2
aws --endpoint-url https://garage-s3.company.ltd s3 cp yellow.jpeg s3://garage.company.ltd
curl https://garage.company.ltd/yellow.jpeg
We’ll be storing backups here so there’s no point in making this available over the UI. Let’s make the bucket private again
1
docker exec -it garage /garage bucket website --decline garage.company.ltd
download the AWS CLI
1
2
3
4
5
6
7
8
# for amd x86 cpus:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
# for arm/multi arch:
curl "https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
aws --version
Configure the AWS CLI for Garage
1
2
3
aws configure set aws_access_key_id <>
aws configure set aws_secret_access_key <>
aws configure set default.region garage
testing the sync feature and look at some files:
1
2
3
4
5
6
mkdir syncdir
touch syncdir/yellow
aws --endpoint-url https://garage-s3.company.ltd s3 cp yellow s3://garage.company.ltd
aws --endpoint-url https://garage-s3.company.ltd s3 ls s3://garage.company.ltd
echo "apple" > syncdir/yellow
aws --endpoint-url https://garage-s3.company.ltd s3 sync ./syncdir s3://garage.company.ltd
list existing assets
1
2
3
aws --endpoint-url https://garage-s3.company.ltd s3 ls s3://garage.company.ltd
aws --endpoint-url https://garage-s3.company.ltd s3 ls s3://garage.company.ltd | \
awk '{if ($3 != "") printf "%s %s %8.2f GB %s\n", $1, $2, $3/1024/1024/1024, $4; else print $0}'
download the file we touched earlier
1
aws --endpoint-url https://garage-s3.company.ltd s3 cp s3://garage.company.ltd/yellow - | less
remove everything inside the bucket
1
aws --endpoint-url https://garage-s3.company.ltd s3 rm s3://garage.company.ltd --recursive
download a file
1
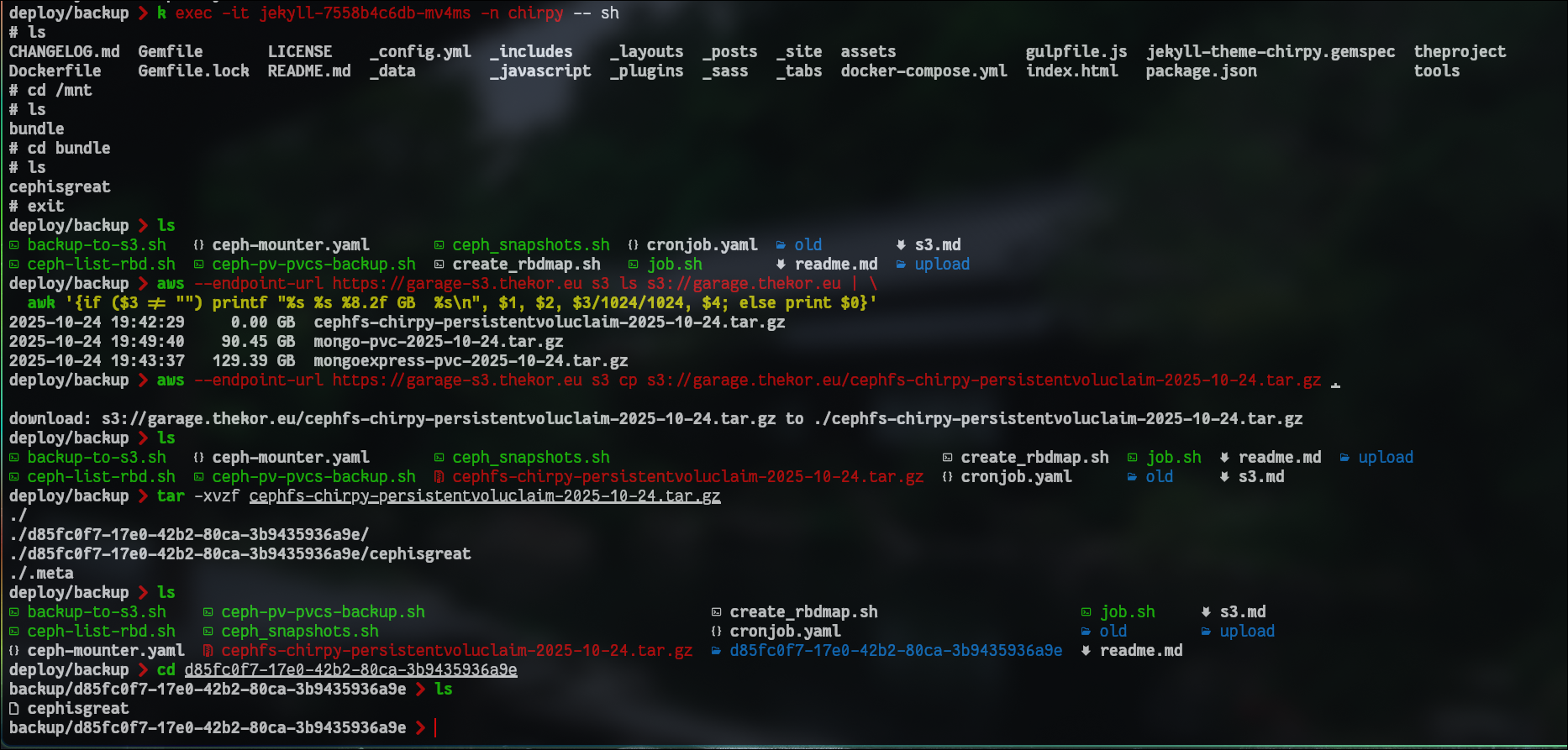
aws --endpoint-url https://garage-s3.company.ltd s3 cp s3://garage.company.ltd/cephfs-chirpy-persistentvoluclaim-2025-10-24.tar.gz .
We’ll also want to a policy to rotate backups otherwise we’ll run out of space eventually
1
2
3
4
5
6
7
8
9
10
11
12
13
cat <<EOF >> policy.json
{
"Rules": [
{
"ID": "DeleteOldBackups",
"Status": "Enabled",
"Filter": {"Prefix": ""},
"Expiration": {"Days": 30},
"NoncurrentVersionExpiration": {"NoncurrentDays": 7}
}
]
}
EOF
apply the policy
1
2
3
aws --endpoint-url https://garage-s3.company.ltd s3api put-bucket-lifecycle-configuration \
--bucket garage.company.ltd \
--lifecycle-configuration file://policy.json
verify it got applied correctly
1
aws --endpoint-url https://garage-s3.company.ltd s3api get-bucket-lifecycle-configuration --bucket garage.company.ltd
Archiving the images and filesystems
Firstly, we’ll need a script that goes through all of the PV’s and PVC’s to determine which ones are block vs filesystems. Once that’s done we’ll rename everything so that we can easily recognize which deployment they relate to. Finally we’ll try to push those archives to our S3 storage. A backup storage should of course always be “pull” based but we’re testing the waters here first. It’s better to start simple and add complexity as we go as opposed to trying to make everything perfect from the get-go.
A. loop over the PVC’s on all of your namespaces
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#!/bin/bash
declare -A pvc_volumes
# Loop over all PVCs in all namespaces
kubectl get pvc --all-namespaces -o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{"\n"}{end}' | while read ns pvc; do
# Get the PV bound to this PVC
pv=$(kubectl get pvc $pvc -n $ns -o jsonpath='{.spec.volumeName}' 2>/dev/null)
if [ -z "$pv" ]; then
continue
fi
# --- Handle CephFS PVCs ---
subvol=$(kubectl get pv $pv -o jsonpath='{.spec.csi.volumeAttributes.subvolumeName}' 2>/dev/null)
pool=$(kubectl get pv $pv -o jsonpath='{.spec.csi.volumeAttributes.pool}' 2>/dev/null)
if [ -n "$subvol" ]; then
echo "PVC: $ns/$pvc → CephFS subvolume: $subvol, Pool: $pool"
pvc_volumes["$subvol"]=1
continue
fi
# --- Handle RBD PVCs ---
volhandle=$(kubectl get pv $pv -o jsonpath='{.spec.csi.volumeHandle}' 2>/dev/null)
if [ -n "$volhandle" ]; then
# Extract the UUID part from the CSI internal name
# Example: 0001-0009-rook-ceph-0000000000000001-41a3ec65-4e77-4fd3-bafa-7f90cb6c1e1a
uuid=$(echo $volhandle | awk -F'-' '{print $(NF-4)"-"$(NF-3)"-"$(NF-2)"-"$(NF-1)"-"$NF}')
rbd_image="csi-vol-$uuid"
echo "PVC: $ns/$pvc → RBD image: $rbd_image"
pvc_volumes["$rbd_image"]=1
continue
fi
# If neither, skip
echo "PVC: $ns/$pvc → No CSI volume found"
done
Running the script above returns this output in the command line
1
2
3
PVC: chirpy/chirpy-persistentvoluclaim → CephFS subvolume: csi-vol-7197f8d2-1332-4a9b-bc19-2c90e97f685b, Pool: myfs-data0
PVC: mongodb/mongo-pvc → RBD image: csi-vol-3be02bf7-c1b3-4acc-ae93-eef11ea1c370
(...)
B. The backup agent
I didn’t want to create services and open the ceph monitor ports outside of the kubernetes cluster so I’ll run the backups from within the cluster and push them to S3 from the pod as well. To do so I’ve prepared a deployment with a persistent storage. You can get away without persistent storage but I realized I didn’t have enough space to copy the images into the root partition so the only solution was to use a PVC.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
apiVersion: v1
kind: Pod
metadata:
name: ceph-mounter
namespace: rook-ceph
spec:
restartPolicy: Never
securityContext:
runAsUser: 0
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- kube-node1
containers:
- name: ceph-mounter
image: rook/ceph:v1.15.5
command: ["bash"]
stdin: true
tty: true
securityContext:
privileged: true
volumeMounts:
- name: ceph-conf
mountPath: /mnt/ceph
- name: dev
mountPath: /dev
- name: backupoutput
mountPath: /root/backupoutput
- name: tmp-backup-dir
mountPath: /tmp
volumes:
- name: ceph-conf
hostPath:
path: /etc/ceph
type: Directory
- name: dev
hostPath:
path: /dev
type: Directory
- name: tmp-backup-dir
persistentVolumeClaim:
claimName: backup-pvc
- name: backupoutput
hostPath:
path: /mnt/backupoutput
type: DirectoryOrCreate
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: backup-pvc
namespace: rook-ceph
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
C. the “builder” backup script
Now we go one step further and create a builder script that generates the ceph commands needed to trigger the backup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
#!/bin/bash
# /mnt/backupoutput/backup-to-s3.sh
ROOK_NAMESPACE="rook-ceph"
RBD_POOL="replicapool"
CEPHFS_NAME="myfs"
CEPHFS_GROUP="csi"
OUTFILE="generated.sh"
S3_BUCKETNAME="garage.company.ltd"
S3_API="https://garage-s3.company.ltd"
CEPH_CONF="/mnt/ceph/ceph.conf"
CEPH_KEYRING="/mnt/ceph/keyring"
BACKUP_DIR="/tmp"
source .env
# === PREPARE OUTPUT ===
echo "#!/bin/bash" > "$OUTFILE"
echo "" >> "$OUTFILE"
echo "if ! which aws > /dev/null 2>&1; then" >> "$OUTFILE"
echo " echo \"installing the aws cli ...\"" >> "$OUTFILE"
echo " /root/backupoutput/aws/install" >> "$OUTFILE"
echo " aws configure set aws_access_key_id $aws_access_key_id" >> "$OUTFILE"
echo " aws configure set aws_secret_access_key $aws_secret_access_key" >> "$OUTFILE"
echo " aws configure set default.region $region" >> "$OUTFILE"
echo "fi" >> "$OUTFILE"
# === GET TOOLBOX POD ===
TOOLBOX_POD=$(kubectl -n $ROOK_NAMESPACE get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}' 2>/dev/null)
if [ -z "$TOOLBOX_POD" ]; then
echo "❌ Could not find rook-ceph-tools pod in namespace $ROOK_NAMESPACE"
exit 1
fi
echo "" >> "$OUTFILE"
echo "echo \"Backup started\"" >> "$OUTFILE"
echo "" >> "$OUTFILE"
echo "mkdir -p /mnt/myfs" >> "$OUTFILE"
echo "ceph-fuse /mnt/myfs -n client.admin --keyring $CEPH_KEYRING -c $CEPH_CONF" >> "$OUTFILE"
# === GET ALL PVCs ===
mapfile -t pvcs < <(kubectl get pvc --all-namespaces -o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" "}{.spec.volumeName}{" "}{.spec.storageClassName}{"\n"}{end}')
for line in "${pvcs[@]}"; do
ns=$(echo "$line" | awk '{print $1}')
pvc=$(echo "$line" | awk '{print $2}')
pv=$(echo "$line" | awk '{print $3}')
sc=$(echo "$line" | awk '{print $4}')
if [ -z "$pv" ]; then
continue
fi
# Get the volume handle (contains the UUID)
volhandle=$(kubectl get pv "$pv" -o jsonpath='{.spec.csi.volumeHandle}' 2>/dev/null)
if [ -z "$volhandle" ]; then
continue
fi
# Extract the UUID safely (works for all formats)
uuid=$(echo "$volhandle" | grep -oE '[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}')
[ -z "$uuid" ] && continue
if [[ "$pvc" == "backup-pvc" ]]; then
continue
fi
# === CASE 1: RBD PVC ===
if [[ "$sc" == *"block"* ]]; then
img="csi-vol-$uuid"
snap_name="backup-$(date +%F)-${ns}-${pvc}"
echo "# RBD backup: $ns/$pvc" >> "$OUTFILE"
echo "rbd --conf $CEPH_CONF --keyring $CEPH_KEYRING map $RBD_POOL/$img &" >> "$OUTFILE"
echo "sleep 5" >> "$OUTFILE"
echo "dd if=/dev/rbd1 of=$BACKUP_DIR/$pvc-$(date +%F).img bs=4M status=progress" >> "$OUTFILE"
echo "cd $BACKUP_DIR && tar -czf $pvc-$(date +%F).tar.gz $pvc-$(date +%F).img && rm $pvc-$(date +%F).img" >> "$OUTFILE"
echo "aws --endpoint-url $S3_API s3 cp $BACKUP_DIR/$pvc-$(date +%F).tar.gz s3://$S3_BUCKETNAME" >> "$OUTFILE"
echo "rbd --conf $CEPH_CONF --keyring $CEPH_KEYRING unmap $RBD_POOL/$img &" >> "$OUTFILE"
echo "rm $BACKUP_DIR/$pvc-$(date +%F).tar.gz" >> "$OUTFILE"
echo "sleep 5" >> "$OUTFILE"
echo "" >> "$OUTFILE"
# === CASE 2: CephFS PVC ===
elif [[ "$sc" == *"cephfs"* ]]; then
subvol="csi-vol-$uuid"
snap_name="backup-$(date +%F)-${ns}-${pvc}"
echo "# CephFS backup: $ns/$pvc" >> "$OUTFILE"
echo "cd /mnt/myfs/volumes/csi/$subvol && tar -czf $BACKUP_DIR/cephfs-${pvc}-$(date +%F).tar.gz . && cd $BACKUP_DIR" >> "$OUTFILE"
echo "aws --endpoint-url $S3_API s3 cp cephfs-${pvc}-$(date +%F).tar.gz s3://$S3_BUCKETNAME" >> "$OUTFILE"
echo "rm cephfs-${pvc}-$(date +%F).tar.gz" >> "$OUTFILE"
echo "" >> "$OUTFILE"
fi
done
echo "echo \"Backup done\"" >> "$OUTFILE"
echo "umount /mnt/myfs" >> "$OUTFILE"
chmod +x "$OUTFILE"
echo "✅ Backup commands written to $OUTFILE"
This should create an executable called generated.sh with the input:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#!/bin/bash
# generated.sh
if ! which aws > /dev/null 2>&1; then
echo "installing the aws cli ..."
/root/backupoutput/aws/install
aws configure set aws_access_key_id <redacted>
aws configure set aws_secret_access_key <redacted>
aws configure set default.region <redacted>
fi
echo "Backup started"
mkdir -p /mnt/myfs
ceph-fuse /mnt/myfs -n client.admin --keyring /mnt/ceph/keyring -c /mnt/ceph/ceph.conf
# CephFS backup: chirpy/chirpy-persistentvoluclaim
cd /mnt/myfs/volumes/csi/csi-vol-7197f8d2-1332-4a9b-bc19-2c90e97f685b && tar -czf /tmp/cephfs-chirpy-persistentvoluclaim-2025-10-24.tar.gz . && cd /tmp
aws --endpoint-url https://garage-s3.company.ltd s3 cp cephfs-chirpy-persistentvoluclaim-2025-10-24.tar.gz s3://garage.company.ltd
rm cephfs-chirpy-persistentvoluclaim-2025-10-24.tar.gz
# RBD backup: mongodb/mongo-pvc
rbd --conf /mnt/ceph/ceph.conf --keyring /mnt/ceph/keyring map replicapool/csi-vol-3be02bf7-c1b3-4acc-ae93-eef11ea1c370 &
sleep 5
dd if=/dev/rbd1 of=/tmp/mongo-pvc-2025-10-24.img bs=4M status=progress
cd /tmp && tar -czf mongo-pvc-2025-10-24.tar.gz mongo-pvc-2025-10-24.img && rm mongo-pvc-2025-10-24.img
aws --endpoint-url https://garage-s3.company.ltd s3 cp /tmp/mongo-pvc-2025-10-24.tar.gz s3://garage.company.ltd
rbd --conf /mnt/ceph/ceph.conf --keyring /mnt/ceph/keyring unmap replicapool/csi-vol-3be02bf7-c1b3-4acc-ae93-eef11ea1c370 &
rm /tmp/mongo-pvc-2025-10-24.tar.gz
sleep 5
echo "Backup done"
umount /mnt/myfs
In case we add new PVC’s in the future they will all automatically get included in the generated.sh.
D. Putting it all together
1
2
3
4
5
#!/bin/bash
# /usr/local/bin/backup-rbd-cephfs.sh
cd /mnt/backupoutput
./backup-to-s3.sh
kubectl exec -it ceph-mounter -n rook-ceph -- /root/backupoutput/generated.sh
1
2
3
cat <<EOF >> /etc/crontab
5 4 * * * root /usr/local/bin/backup-rbd-cephfs.sh
EOF
E. Verify
To verify everything went as planned run the commands below. I’ve created a dummy file in the cephfs mount point called “cephisgreat”. Once I download my archive it should be inside.
Moving the trigger outside of the cluster
As explained in the introduction, having backups triggered by the cluster itself is an anti-pattern. If one of our nodes get compromissed for some reason there’s nothing stopping ransomware from tainting our backups as well. Let’s reverse that by having the agent control and trigger all the actions from a VPS machine running in someone else’s machine.
I’ve bound the ceph-mounter pod to the node1 with affinity rules so that I can make it available over ssh. The only thing left to do is: 1) create the role for the backup operator to access the cluster with kubectl and 2) setup a secure shell with asymetric keys
A. Backup operator role
save the manifest as backup-operator-role.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
cat <<EOF >> backup-operator-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: backup-operator-readonly
rules:
# Read access to all standard resources except Secrets
- apiGroups: [""]
resources:
- pods
- pods/log
- pods/exec
- services
- configmaps
- persistentvolumes
- persistentvolumeclaims
- namespaces
- nodes
verbs: ["get", "list", "watch", "create"] # "create" needed for pods/exec
# Read access to workloads (Deployments, StatefulSets, etc.)
- apiGroups: ["apps"]
resources:
- deployments
- statefulsets
- daemonsets
- replicasets
verbs: ["get", "list", "watch"]
# Read access to batch jobs and cronjobs
- apiGroups: ["batch"]
resources:
- jobs
- cronjobs
verbs: ["get", "list", "watch"]
# Optionally include storage classes, volume snapshots, etc.
- apiGroups: ["storage.k8s.io"]
resources:
- storageclasses
- volumeattachments
verbs: ["get", "list", "watch"]
# Optionally include CRDs (if your backup system needs to inspect them)
- apiGroups: ["apiextensions.k8s.io"]
resources:
- customresourcedefinitions
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: backup-operator-readonly-binding
subjects:
- kind: ServiceAccount
name: backup-operator
namespace: backup
roleRef:
kind: ClusterRole
name: backup-operator-readonly
apiGroup: rbac.authorization.k8s.io
EOF
Configure the service account
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
kubectl create namespace backup
kubectl create serviceaccount backup-operator -n backup
cat <<EOF > backup-operator-token.yaml
apiVersion: v1
kind: Secret
metadata:
name: backup-operator-token
namespace: backup
annotations:
kubernetes.io/service-account.name: backup-operator
type: kubernetes.io/service-account-token
EOF
kubectl apply -f backup-operator-token.yaml
kubectl apply -f backup-operator-role.yaml
kubectl -n backup patch serviceaccount backup-operator -p '{"secrets":[{"name":"backup-operator-token"}]}'
extract the secrets
1
2
3
4
SECRET=$(kubectl -n backup get sa backup-operator -o jsonpath='{.secrets[0].name}')
TOKEN=$(kubectl -n backup get secret $SECRET -o jsonpath='{.data.token}' | base64 --decode)
CA=$(kubectl -n backup get secret $SECRET -o jsonpath='{.data.ca\.crt}' | base64 --decode)
SERVER=$(kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}')
And finally generate the kubeconfig for the service account
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cat <<EOF > backup-operator.kubeconfig
apiVersion: v1
kind: Config
clusters:
- name: kubernetes
cluster:
certificate-authority-data: $(echo $CA | base64 | tr -d '\n')
server: $SERVER
contexts:
- name: backup-operator-context
context:
cluster: kubernetes
user: backup-operator
users:
- name: backup-operator
user:
token: $TOKEN
current-context: backup-operator-context
EOF
B. Secure shell
The operator will need a user on node1 and an ssh key. The operator’s public key is then stored on node1 and the routing is setup to allow the source/static NAT to masquerade the requests onto our node1.
The trigger on the backup machine would look something like this:
1
2
3
4
5
6
7
8
9
10
11
#!/bin/bash
# /usr/local/bin/backup-rbd-cephfs.sh
# cron doesn't have access to the path
# so we need to specify it manually
export PATH=/usr/local/bin:/usr/bin:/bin
export HOME=/root
ssh -f -N -L 6443:127.0.0.1:6443 kube-node1
scp /root/kubernetes/backup-to-s3.sh kube-node1:/mnt/backupoutput
ssh kube-node1 "cd /mnt/backupoutput && ./backup-to-s3.sh && kubectl exec -i ceph-mount -n rook-ceph -- /root/backupoutput/generated.sh"
kill $(lsof -t -i:6443)
store your alias in .ssh/config
1
2
3
4
Host kube-node1
HostName <public ip>
User <not root>
Port 22