
Introduction
Thought I would write a diary entry with my two blunders of the week. The first one is related to a ceph cluster manipulation that killed a live production server on a busy thursday morning and the second was a ZFS mistake that deleted my secondary backup.
“Smart” tools
My colleague had the brilliant idea of setting up a ceph cluster for our production cluster at work. I had the chance to do some testing at the time and knew I could move around my virtual machines without losing any tcp packets but we never got any official training on this. What I didn’t know that morning was that by migrating a machine into a node, proxmox’s high availability feature would try to redistribute the load by migrating a perfectly healthy machine into another node. Makes sense? Why not sure, except the VM was migrated to a node that did NOT have enough RAM so it killed the perfectly healthy machine.
ZFS mistake
Woke up this morning to backup some important data into a backup server. As I ran my rsync script in a tmux session and was surprised to see that the logs were just frozen since an hour which is highly unusual since my files are rather small.
The ring buffer would give me a lead on what to do next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
root@proxmox01:$ journalctl --since today | grep -Ei "fail|error|panic"
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=2 offset=2800334204928 size=335872 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=1 offset=2662983024640 size=16384 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=2 offset=2821800898560 size=20480 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2804618608640 size=28672 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=1 offset=270336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=2645727305728 size=4096 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=2 offset=2800334204928 size=368640 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=2662983020544 size=16384 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2804618539008 size=69632 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=1 offset=1466335498240 size=16384 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=1466335494144 size=16384 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=270336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=1 offset=270336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=1 offset=1466335498240 size=16384 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=4000776200192 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=1 offset=4000776200192 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=1 offset=4000776462336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=1 offset=270336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=1 offset=4000776462336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=2 offset=2800334540800 size=32768 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=2 offset=2804618493952 size=151552 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=1 offset=4000776200192 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=1 offset=4000776200192 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=1 offset=4000776462336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2800334483456 size=94208 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2804618551296 size=94208 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=1 offset=4000776462336 size=8192 flags=721089
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=2 offset=2804618510336 size=135168 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdc1 error=5 type=2 offset=2808925626368 size=24576 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2804618637312 size=4096 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2800334204928 size=368640 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2813208293376 size=28672 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2813208297472 size=24576 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2808925102080 size=548864 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2817521688576 size=20480 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2808925089792 size=557056 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2821800894464 size=20480 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2826108043264 size=28672 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2826108100608 size=4096 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdh1 error=5 type=2 offset=2830388789248 size=4096 flags=1572992
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2817521192960 size=516096 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2817520144384 size=1048576 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sda1 error=5 type=2 offset=2821800890368 size=28672 flags=1074267264
Apr 18 14:19:22 proxmox01 kernel: zio pool=larger vdev=/dev/sdd1 error=5 type=1 offset=2645727305728 size=4096 flags=1572992
I realized something was wrong with either my zfs pool or one or more disks were failing as I couldn’t list the contents of the zfs partition. Running a basic status on the pool revealed the problem zpool status <name of the pool>:
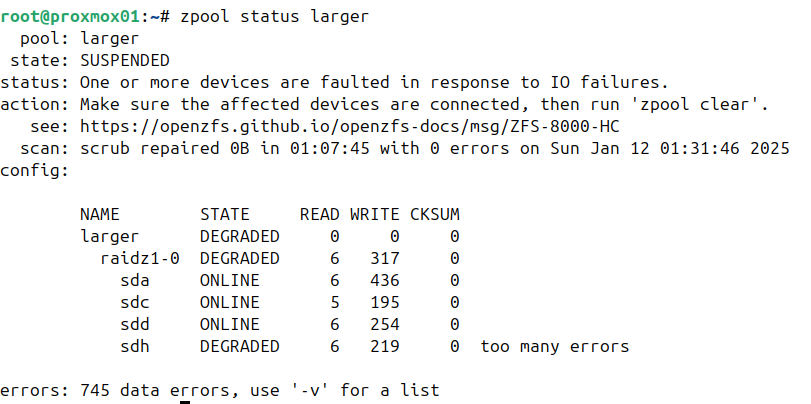
/dev/sdh is thowing errors so I’ll just assume the drive is dead and replace it. It’s a RAIDZ1 so I can afford to lose (at most) 1 drive. The only thing is I don’t know where it is located on the backplane.
A quick google search tells me I should install this package and run the command:
1
2
root@proxmox01:$ apt install ledmon
root@proxmox01:$ ledctl locate=/dev/sdh
The command threw an error so I suppose my old motherboard is not supported. And this is where I made the mistake of trusting the output of fdisk /dev/sdh. I only looked at the disk model thinking it would be enough but it turns out I have two identical western digital reds with the same model number running in that ZFS pool and replaced the wrong drive (sigh).
1
2
root@proxmox01:$ lspci | grep -i raid
0a:00.0 RAID bus controller: Areca Technology Corp. ARC-1680 series PCIe to SAS/SATA 3Gb RAID Controller
Another teaching I got was that my raid controller needs to reconfigure drives when doing a hot swap. I tried to look at the manual to try and set the newly added disks in “passthrough” mode through the cli but I couldn’t get it to work. I had previously unplugged the ethernet cable that goes into the Areca so I couldn’t reach areca’s http server either. The archttp UI would have looked something like this and would have allowed me (I assume) to hot swap my drive:
By interrupting the boot process with F6 and getting into the areca’s menu I was able to make that change.
But now I’m surprised to see that zfs cannot find the pool anymore when running zpool list. Trying to import the pool with zpool import <name of the pool> didn’t do the trick so I guess I’ll just recreate it with the same name i.e. “larger”
1
root@proxmox01:$ zpool create -f -o ashift=12 larger raidz1 /dev/sda /dev/sdc /dev/sdd /dev/sdh
I didn’t previously format the disk which had some kind of mdadm array on it so the command above failed. I used the fdisk with the d option to delete the partition and ran the following command to stop the mdadm raid on the newly added drive.
1
2
root@proxmox01:$ mdadm --stop /dev/md127
mdadm: stopped /dev/md127
These two changes did the trick for me and the pool is now healthy again.
Conclusion
#1 Don’t set up settings on a ceph cluster without doing proper testing with production grade VMs for load testing and looking at the edge cases
#2 I’ll probably replace those western digital drives with seagates because of how greedy they were when trying to sell SMR drives in 2023. It’s not a good idea for a business to trick its customers and I’ll protest with the only thing they understand: by giving my money to competitors. If you’re not familiar with the controversy here’s an article that explains it
#3 No matter how much documentation you have there will always be use cases you never seen before. Having a homelab with production applications is the only way I found to safely go through those use cases and learn from mistakes. No amount of certifications can replace the experience of rebuilding a cluster once a drive fails
#4 I should look into re-installing and using more advanced partitions like btrfs or zfs. Zfs has the zfsreplication command that is apparently a lot faster than rsync. I did a bit of testing with btrfs in this article but I think I’ll give ZFS on my daily driver a try some day
#5 udevadm info --name=/dev/sdh | grep ID_SCSI_SERIAL would have done the trick and given me the drive’s serial number
Thanks for sticking around and see you on the next one